
数据标注
什么是数据标注?
在机器学习中,数据标注流程用于识别原始数据(图片、文本文件、视频等)并添加一个或多个有意义的信息标签以提供上下文,从而使机器学习模型能够从中进行学习。例如,标签可指示相片是否包含鸟或汽车、录音中有哪些词发音,或者 X 影像是否包含肿瘤。各种使用案例都需要用到数据标记,包括计算机视觉、自然语言处理和语音识别。
要理解数据标注,得先理解AI其实是部分替代人的认知功能。回想一下我们是如何学习的,例如我们学习认识苹果,那么就需要有人拿着一个苹果到你面前告诉你,这是一个苹果。然后以后你遇到了苹果,你才知道这玩意儿叫做“苹果”。
类比机器学习,我们要教他认识一个苹果,你直接给它一张苹果的图片,它是完全不知道这是个啥玩意的。我们得先有苹果的图片,上面标注着“苹果”两个字,然后机器通过学习了大量的图片中的特征,这时候再给机器任意一张苹果的图片,它就能认出来了。
这边可以顺带提一下训练集和测试集的概念。训练集和测试集都是标注过的数据,还是以苹果为例子,假设我们有1000张标注着“苹果”的图片,那么我们可以拿900涨作为训练集,100张作为测试集。机器从900张苹果的图片中学习得到一个模型,然后我们将剩下的100张机器没有见过的图片去给它识别,然后我们就能够得到这个模型的准确率了。想想我们上学的时候,考试的内容总是不会和我们平时的作业一样,也只有这样才能测试出学习的真正效果,这样就不难理解为什么要划分一个测试集了。
我们知道机器学习分为有监督学习和无监督学习。无监督学习的效果是不可控的,常常是被用来做探索性的实验。而在实际产品应用中,通常使用的是有监督学习。有监督的机器学习就需要有标注的数据来作为先验经验。
在进行数据标注之前,我们首先要对数据进行清洗,得到符合我们要求的数据。数据的清洗包括去除无效的数据、整理成规整的格式等等。具体的数据要求可以和算法人员确认。
数据标记的工作原理
今天,最实用的机器学习模型利用的是监督学习,它应用算法以将一个输入映射到一个输出。为了使监督学习发挥作用,您需要一组带标签的数据,使模型能够从中学习以做出正确的决定。数据标记的起点通常是要求人类就指定的无标签数据做出判断。例如,标记者可能需要为数据集中“相片是否包含鸟”的答案为“是”的所有图片添加标签。添加标签可能像简单的是/否一样粗疏,也可能像识别图片中与鸟相关的像素一样精细。机器学习模型在名为“模型训练”的流程中,使用人类提供的标签学习背后的模式。 这样训练过的模型,可用于对新数据进行预测。
在机器学习中,您用作客观标准来训练和评估指定模型的正确标记的数据集通常称为“标准答案”。 训练过的模型的准确度将取决于标准答案的准确度,因此请付出一些时间和资源来确保高准确度的数据标记至关重要。
几种常见的数据标注类型
计算机视觉
构建计算机视觉系统时,首先需要标记图片、像素或关键点,或者创建完全包围数字图片的界限(称为边界框),以生成训练数据集。例如,您可以按质量类型(例如,产品与生活方式图片)或内容(图片自身实际包含的内容)对图片进行分类,也可以在指定的像素级别分割图片。然后,您可以使用这些训练数据构建计算机视觉模型,该模型可用于自动对图片进行分类、检测对象的位置、识别图片中的关键点,或分割图片。
自然语言处理
自然语言处理要求您首先手动识别文本中的重要部分或使用特定标签来标记文本,以生成您的训练数据集。例如,您可能想要确定文本广告的观点或意图、识别语音中的部分、归类地点和人名之类的专有名词,并识别图片、PDF 或其他文件中的文字。为此,您可以在文字周围绘制边界框,然后手动将这些文字转录到训练数据集。自然语言处理模型用于情感分析、实体名称识别和光学字符识别。
音频处理
音频处理可以将所有类型的声音,例如语音、野生动物噪音(吠声、嚎叫或鸟鸣)和建筑声音(打碎玻璃、扫描或警报),转换成结构化格式,以便用于机器学习。音频处理通常要求您首先手动将其转录为书面文本。然后,您可以通过添加标签并对音频进行分类,找出关于该音频的更深层的信息。这种经过分类的音频成为您的训练数据集。
1.分类标注:分类标注,就是我们常见的打标签。一般是从既定的标签中选择数据对应的标签,是封闭集合。如下图,一张图就可以有很多分类/标签:成人、女、黄种人、长发等。对于文字,可以标注主语、谓语、宾语,名词动词等。
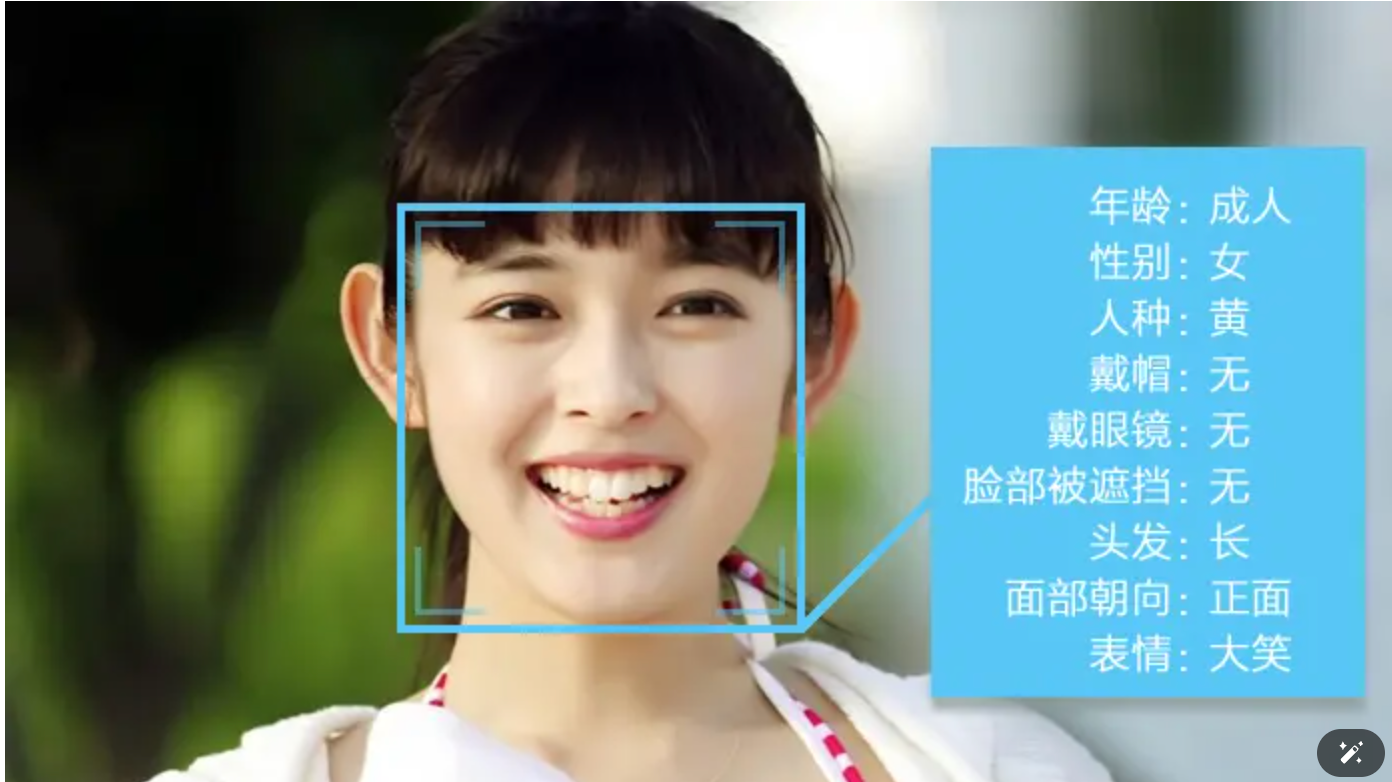
适用:文本、图像、语音、视频
应用:脸龄识别,情绪识别,性别识别
2.标框标注:机器视觉中的标框标注,很容易理解,就是框选要检测的对象。如人脸识别,首先要先把人脸的位置确定下来。行人识别,如下图。

适用:图像
应用:人脸识别,物品识别
3.区域标注:相比于标框标注,区域标注要求更加精确。边缘可以是柔性的。如自动驾驶中的道路识别。

适用:图像
应用:自动驾驶
4.描点标注:一些对于特征要求细致的应用中常常需要描点标注。人脸识别、骨骼识别等。

适用:图像
应用:人脸识别、骨骼识别
5.其他标注:标注的类型除了上面几种常见,还有很多个性化的。根据不同的需求则需要不同的标注。如自动摘要,就需要标注文章的主要观点,这时候的标注严格上就不属于上面的任何一种了。(或则你把它归为分类也是可以的,只是标注主要观点就没有这么客观的标准,如果是标注苹果估计大多数人标注的结果都差不多。)
三、数据标注的过程
1.标注标准的确定
确定好标准是保证数据质量的关键一步,要保证有个可以参照的标准。一般可以:
- 设置标注样例、模版。例如颜色的标准比色卡。
- 对于模棱两可的数据,设置统一处理方式,如可以弃用,或则统一标注。
参照的标准有时候还要考虑行业。以文本情感分析为例,“疤痕”一词,在心理学行业中,可能是个负面词,而在医疗行业则是一个中性词。
2.标注形式的确定
标注形式一般由算法人员制定,例如某些文本标注,问句识别,只需要对句子进行0或1的标注。是问句就标1,不是问句就标0。
3.标注工具的选择
标注的形式确定后,就是对标注工具的选择了。一般也是由算法人员提供。大公司可能会内部开发一个专门用于数据标注的可视化工具。如:

也有使用开源的数据标注工具的,如推荐 Github 上的小工具labelImg
四、数据标注产品的设计
结合自己做过一款数据标记工具谈谈设计数据标注工具的几个小技巧。
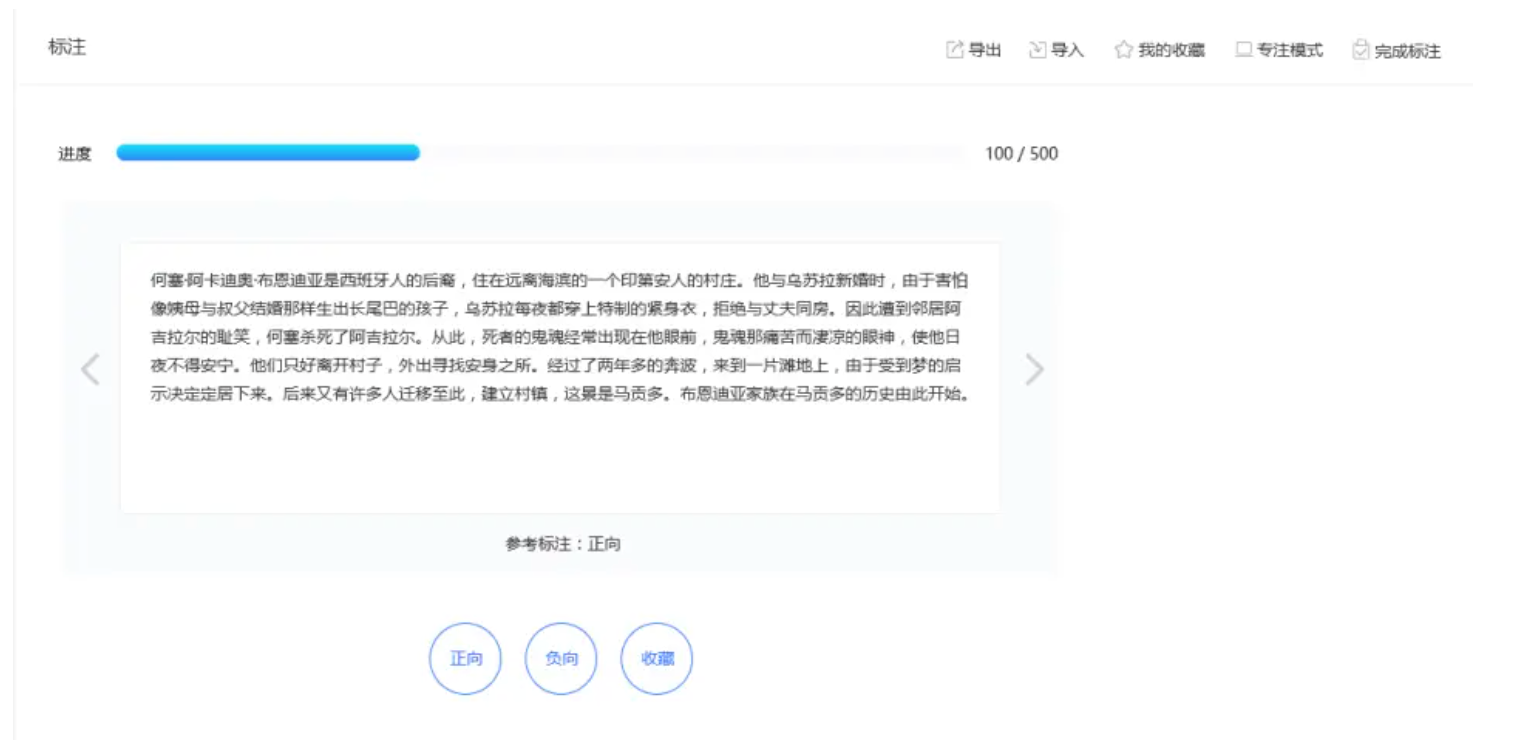
一个数据标注工具一般包含:
- 进度条:用来指示数据标注的进度。标注人员一般都是有任务量要求的,一方面方便标注人员查看进度,一方面方便统计。
- 标注主体:这个可以根据标注形式进行设计,原则上是越简洁易用越好。根据标注所需要的注意力可以分为单个标注和多个标注的形式,可根据需求选择。
- 数据导入导出功能:如果你的标注工具是直接数据对接到模型上的,可以不需要。
- 收藏功能:这个可能是没有接触过数据标注的不会想到。标注人员常常会出现的一种情况就是疲劳,或者是遇到了那种模棱两可的数据,则可以先收藏,等后面再标。
- 质检机制:在分发数据的时候,可以随机分发一些已经标注过的数据,来检测标注人员可靠性。
- Title: 数据标注
- Author: Salmon
- Created at : 2024-09-11 17:11:05
- Updated at : 2024-09-21 10:11:30
- Link: https://salmonsea.top/2024/09/11/数据标注/
- License: This work is licensed under CC BY-NC-SA 4.0.